Structured RerF Demo: Circle Experiment¶
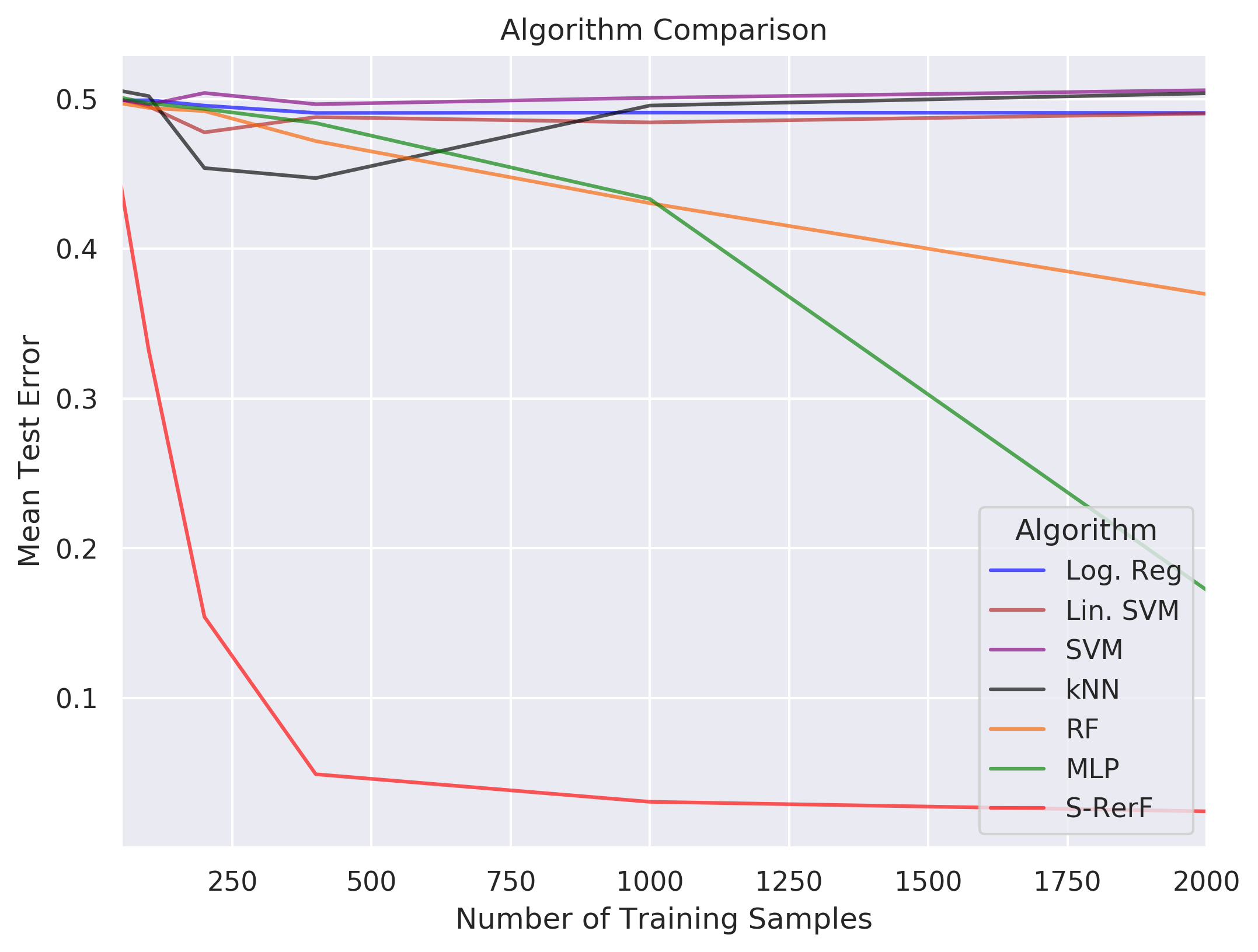
Similar to Figure 14 in this paper, we form a two-class classification problem in which each data point is a discretization of a circle into 100 points. In each class, two non-adjacent sequences of points take on the value one while the rest of the points take on the value zero. In class 0, both sequences are of length five while in class 1 the sequences are of length four and six. Sequences are distributed uniformly and wrap around from the end of the vector to the start if necessary.
We test the performance of S-Rerf and a set of other classification algorithms, training each on samples of sizes \(n \in \{50,100,200,400,1000,2000\}\), each containing an equal number of data points from each class. The average 0-1 loss is evaluated for each algorithm for each training size using a single test set of size \(m=10000\) with an equal number of data points in each class.
[28]:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
%matplotlib inline
import seaborn as sns
import pickle
import time
from tqdm import tqdm
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from rerf.rerfClassifier import rerfClassifier
import warnings
warnings.simplefilter('ignore')
[47]:
def samp(n1,n2):
## Sample objects from each class
n1,n2 = int(n1),int(n2)
X1 = np.empty((n1,100))
Y1 = np.full(n1,0)
for i in range(n1):
cir = np.zeros(100)
s1 = np.random.choice(range(0,100)) # Random Location
l1 = [j%100 for j in range(s1,s1+5)] # Length 5 vector from s1
exclude_idx = set([j%100 for j in range(s1-5,s1+6)])
s2 = np.random.choice(list(set(range(0,100)).difference(exclude_idx)))
l2 = [j%100 for j in set(range(s2,s2+5)).difference(set(l1))]
cir[l1] = 1
cir[l2] = 1
X1[i] = cir
X2 = np.empty((n2,100))
Y2 = np.full(n2,1)
for i in range(n2):
cir = np.zeros(100)
s1 = np.random.choice(range(0,100)) # Random location
l1 = [j%100 for j in range(s1,s1+4)] # Length 4 vector from s1
exclude_idx = set([j%100 for j in range(s1-6,s1+5)])
s2 = np.random.choice(list(set(range(0,100)).difference(exclude_idx)))
l2 = [j%100 for j in set(range(s2,s2+6)).difference(set(l1))]
cir[l1] = 1
cir[l2] = 1
X2[i] = cir
return((np.vstack([X1,X2]),np.hstack([Y1,Y2])))
[115]:
## Generate train and test sets
np.random.seed(1234)
ns = np.array([50,100,200,400,1000,2000])
TRAIN_FRAC = 0.5
ns1 = [int(i*TRAIN_FRAC) for i in ns]
ns2 = ns1
X_train, Y_train = np.empty(shape=(0,100)), np.empty(shape=(0))
for n1,n2 in zip(np.append(ns1[0],np.diff(a=ns1)),
np.append(ns2[0],np.diff(a=ns2))):
x, y = samp(n1,n2)
shuffled_idx = list(range(len(y))); np.random.shuffle(shuffled_idx)
X_train = np.vstack((X_train, x[shuffled_idx]))
Y_train = np.hstack((Y_train, y[shuffled_idx]))
TEST_SIZE = 10000
X_test, Y_test = samp(TEST_SIZE, TEST_SIZE)
[117]:
## Visualize the training data as an image
fig = plt.figure(figsize=(2,2),facecolor='white')
temp = X_train[:50].copy()
temp[np.where(Y_train[:50]==1)[0]] *= 2
plt.imshow(temp)
plt.title("Training sample colored by class, n=50",fontsize=5)
frame1 = plt.gca()
frame1.axes.get_xaxis().set_ticks([])
frame1.axes.get_yaxis().set_ticks([])
plt.tight_layout()
plt.show()

[118]:
## Setup for run, define classifiers to train and test
names = {"Log. Reg": "blue", "Lin. SVM":"firebrick", "SVM":"purple",
"kNN": "black", "RF":"#f86000", "MLP":"green", "S-RerF":"red"}
ncores=1
num_runs=1
n_est=100
classifiers = [
LogisticRegression(random_state=0, n_jobs=ncores, solver='liblinear'),
LinearSVC(),
SVC(C=1.0, kernel='rbf', gamma='auto',random_state=0),
KNeighborsClassifier(3, n_jobs=ncores),
RandomForestClassifier(n_estimators=n_est, max_features='auto', n_jobs=ncores),
MLPClassifier(hidden_layer_sizes=(100, ), random_state=0, max_iter=1000),
rerfClassifier(projection_matrix="S-RerF",
max_features=40,
n_jobs=ncores,
n_estimators=n_est,
oob_score=False,
random_state=0,
image_height=1,
image_width=100,
patch_height_max=1,
patch_height_min=1,
patch_width_max=15,
patch_width_min=1
)
]
[119]:
# Train each classifier on each data set size, then test
## Prep output file:
f = open('s-rerf_circle_runs.csv', 'w+')
f.write("classifier,n,Lhat,trainTime,testTime,iterate\n")
f.flush()
runList = [(n, clf, run) for n in ns\
for clf in zip(classifiers, [key for key in names])\
for run in range(num_runs)]
for n, clf, iteration in tqdm(runList):
X = X_train[:n]
y = Y_train[:n]
trainStartTime = time.time()
clf[0].fit(X, y)
trainEndTime = time.time()
trainTime = trainEndTime - trainStartTime
testStartTime = time.time()
out = clf[0].predict(X_test)
testEndTime = time.time()
testTime = testEndTime - testStartTime
lhat = np.mean(np.not_equal(out, Y_test).astype(int))
####("variable,Lhat,trainTime,testTime,iterate")
f.write(f"{clf[1]}, {n}, {lhat:2.9f}, {trainTime:2.9f}, {testTime:2.9f}, {iteration}\n")
f.flush()
f.close()
100%|██████████| 42/42 [03:59<00:00, 18.24s/it]
[122]:
## Read output file log and plot
dat = pd.read_csv("s-rerf_circle_runs.csv")
d1 = pd.DataFrame(columns = ['classifier', 'n', 'Lhat', 'color'])
k = 0
for ni in np.unique(dat['n']):
for cl in np.unique(dat['classifier']):
tmp = dat[np.logical_and(dat['classifier'] == cl,dat['n'] == ni)][['n', 'Lhat']]
se = stats.sem(tmp['Lhat'])
list(tmp.mean())
d1.loc[k] = [cl] + list(tmp.mean()) + [names[cl]]
k += 1
sns.set(style="darkgrid", rc={'figure.figsize':[12,8], 'figure.dpi': 300})
fig, ax = plt.subplots(figsize = (8,6))
for key in names.keys():
grp = d1[d1['classifier'] == key]
ax = grp.plot(ax=ax, kind='line', x='n', y='Lhat', label=key, \
c = names[key], alpha =0.65)
#ax.set_yscale('log')
plt.legend(loc='lower right',title='Algorithm')
plt.title('Algorithm Comparison')
plt.ylabel('Mean Test Error')
plt.xlabel('Number of Training Samples')
#plt.savefig('./s-rerf_circle_experiment.pdf',dpi=300,format='pdf')
plt.show()