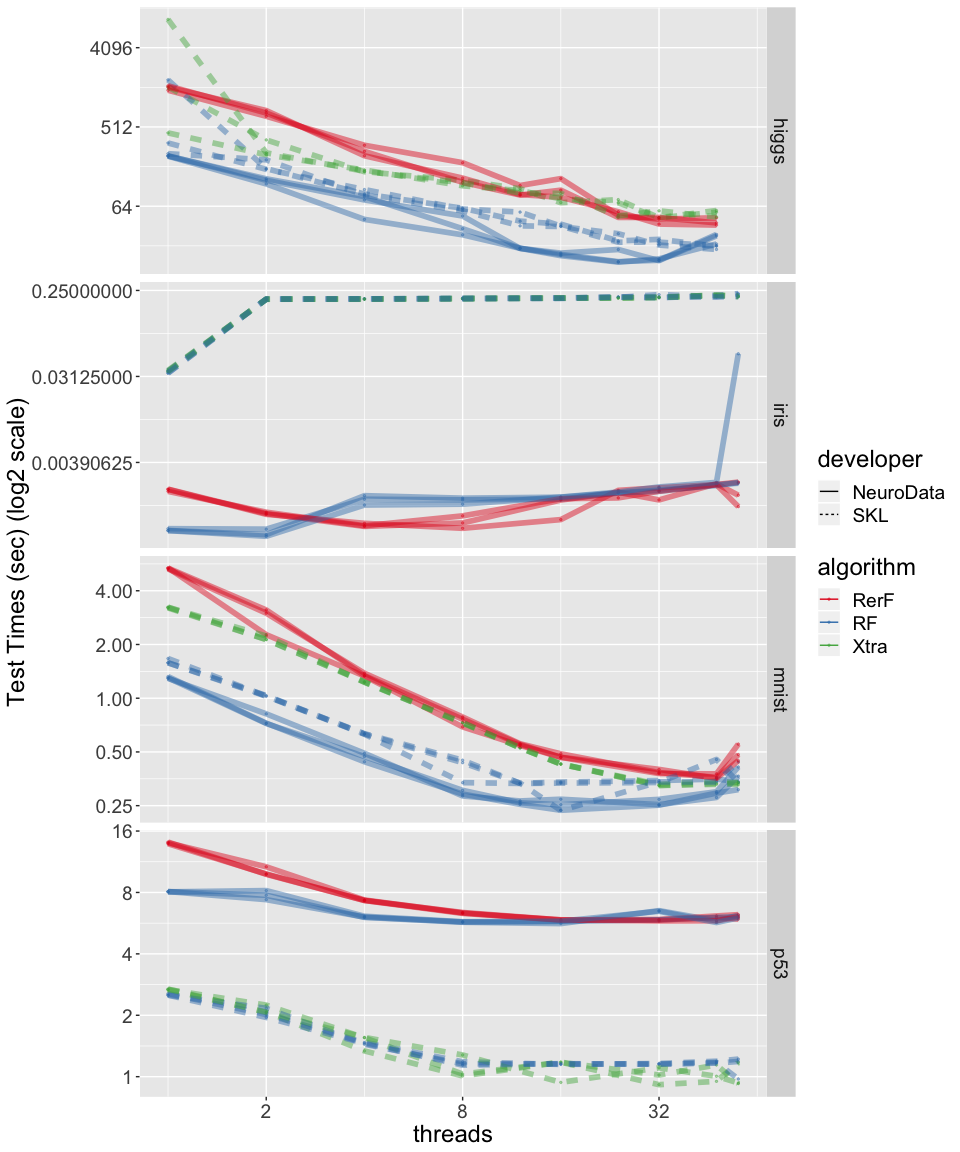
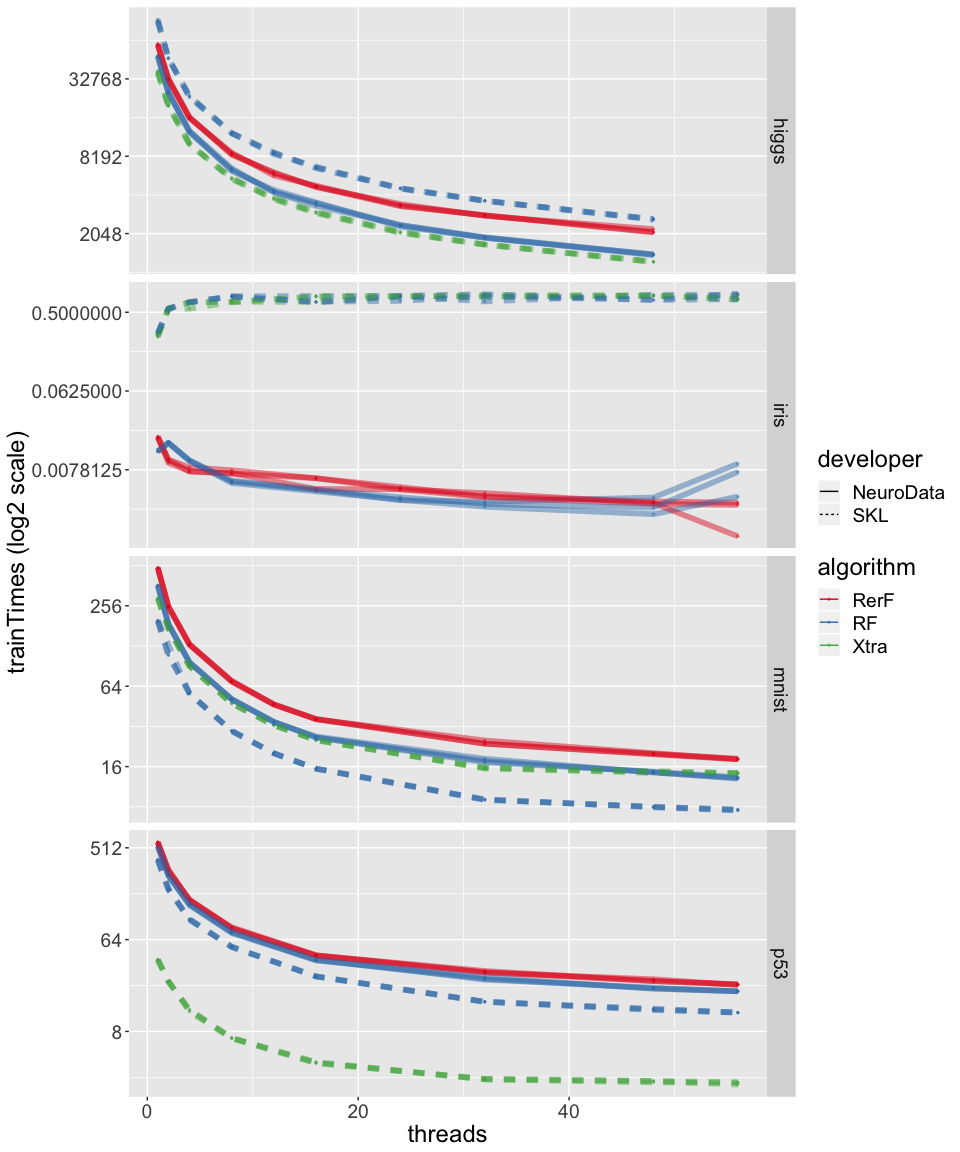
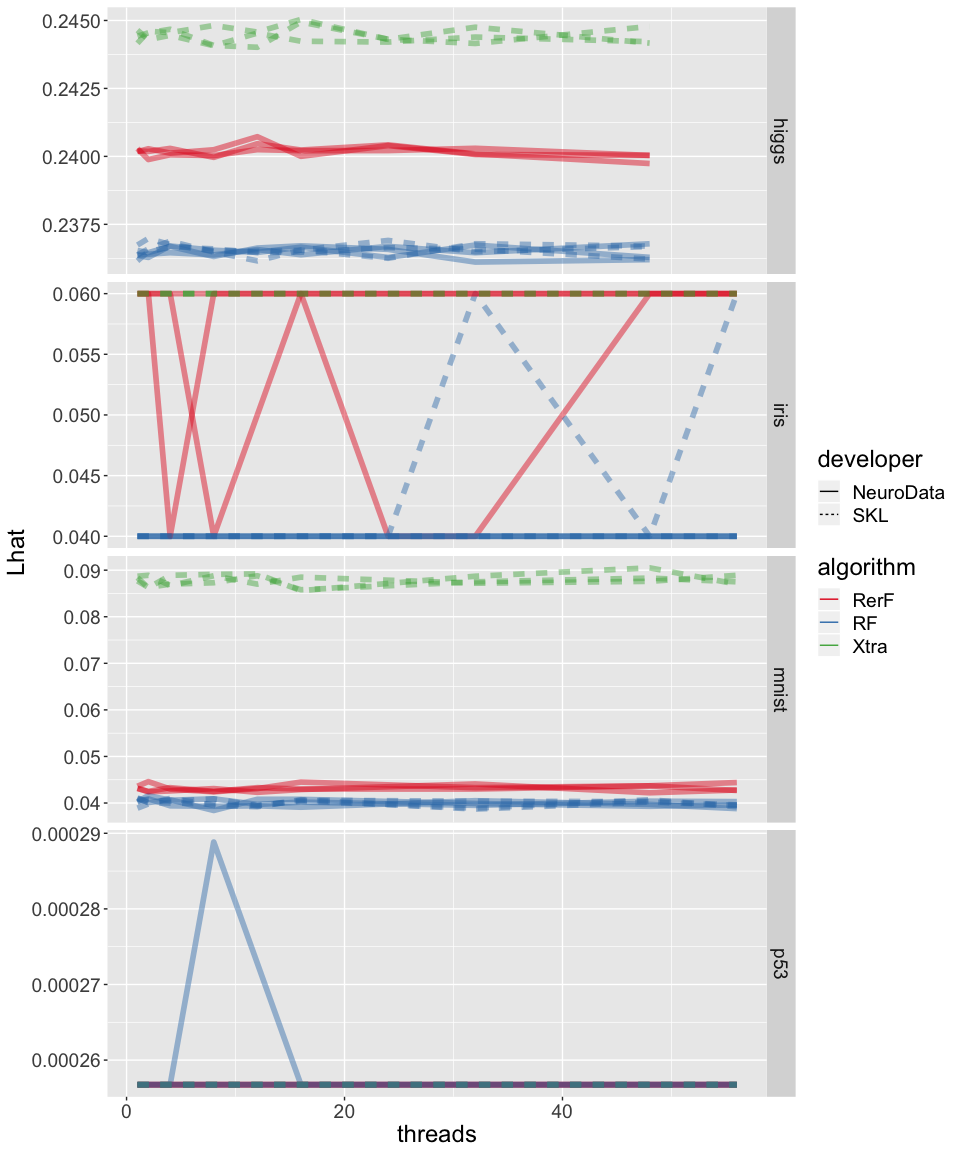
##%%
import pandas as pd
import time, multiprocessing
import numpy as np
import rerf
from rerf.RerF import fastPredict, fastPredictPost, fastRerF
from rerf.rerfClassifier import rerfClassifier
from sklearn import datasets
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
##%%
def loadData(name):
if name == "iris":
print('loading ' + name)
iris = datasets.load_iris()
Xtrain = iris.data
Ytrain = iris.target
Xtest = iris.data
Ytest = iris.target
print("DONE")
if name == "mnist":
print('loading ' + name)
Xtrain = pd.read_csv("./mnist-in-csv/mnist_train.csv", dtype = np.int8)
Ytrain = Xtrain['label']
Xtrain = Xtrain.drop(['label'], axis=1)
Xtest = pd.read_csv("./mnist-in-csv/mnist_test.csv", dtype = np.int8)
Ytest = Xtest['label']
Xtest = Xtest.drop(['label'], axis=1)
print("DONE")
if name == "higgs":
print('loading ' + name)
Xtrain = pd.read_csv("HIGGS.csv", nrows = (11000000 - 500000), header = None)
Ytrain = np.int8(Xtrain[0])
Xtrain = np.asarray(Xtrain.drop([0], axis = 1))
Xtest = pd.read_csv("HIGGS.csv", skiprows = (11000000 - 500000), header = None)
Ytest = np.int8(Xtest[0])
Xtest = np.asarray(Xtest.drop([0], axis=1))
print("DONE")
if name == "p53":
print('loading ' + name)
Xtrain = pd.read_csv("p53_old_2010/K8.nocomma.data", header = None, na_values = "?")
Xtrain = Xtrain.dropna(axis=0)
Ytrain = np.asarray([{'inactive':0, 'active':1}[i] for i in Xtrain[5408]])
Xtrain = np.asarray(Xtrain.drop([5408], axis = 1))
Xtest = pd.read_csv("p53_new_Data Sets/K9.nocomma.data", header = None, na_values = "?")
Xtest = Xtest.dropna(axis=0)
Ytest = np.asarray([{'inactive':0, 'active':1}[i] for i in Xtest[5408]])
Xtest = np.asarray(Xtest.drop([5408], axis=1))
print("DONE")
return Xtrain, Ytrain, Xtest, Ytest
##%%
def run(datasetName, pythonFile, numTrees, NCPU, nruns):
X, Y, Xtest, Ytest = loadData(datasetName)
for ncpu in NCPU:
for iterate in range(1, nruns + 1):
## {Name: {cl: , color:}}
classifiers = {
"Sk-RF": {"cl":RandomForestClassifier(n_estimators=int(numTrees), max_depth = None, n_jobs = int(ncpu)),
"color": "blue"},
"Sk-Xtra": {"cl": ExtraTreesClassifier(n_estimators = int(numTrees), max_depth = None, n_jobs = int(ncpu)),
"color": "purple"},
"ND-pyRF": {"cl": rerfClassifier(n_estimators = int(numTrees),
projection_matrix = "Base", max_depth = None, n_jobs = int(ncpu)),
"color": "red"},
"ND-pyRerF" : {"cl": rerfClassifier(n_estimators = int(numTrees),
projection_matrix = "RerF", max_depth = None, n_jobs = int(ncpu)),
"color": "pink"},
}
for key in classifiers:
with open(pythonFile, 'a') as f:
clf = classifiers[key]['cl']
trainStartTime = time.time()
clf.fit(X, Y)
trainEndTime = time.time()
trainTime = trainEndTime - trainStartTime
testStartTime = time.time()
out = clf.predict(Xtest)
testEndTime = time.time()
testTime = testEndTime - testStartTime
lhat = np.mean(out != Ytest)
f.write(f"{key}, {datasetName}, {ncpu}, {lhat:2.9f}, {trainTime:2.9f}, {testTime:2.9f}, {iterate}\n")
if __name__ == "__main__":
NTREES = 500
NCPU = [1, 2, 4, 8, 16, 32, 48, 56]
NCPU.reverse()
NRUNS = 3
names = ['iris', 'mnist', 'p53', 'higgs']
for ni in names:
pythonFile = "testing_times_python_" + ni + ".csv"
with open(pythonFile, 'w+') as f:
f.write("classifier, dataset, threads, Lhat,trainTime, testTime, iterate\n")
run(ni, pythonFile, NTREES, NCPU, NRUNS)